Distributed ETL? Do's and Don'ts.
A distributed ETL? Why? How? Would you recommend? ✅ ❌
I came across a challenge recently, to explain to a potential pen-pal, about a certain project I had completed recently. The caveat to this question was that the receiver of the communication was someone who was interested in your work, but not necessarily familiar with the terminology. I thought it was a useful exercise so I thought I would share a modified version of my submission. I encourage many of you to do the same!
The project
A recent project we took on, was to build a distributed ETL from scratch, deployed as composable Go services. This sounds confusing… To simplify imagine this, the application, has a database behind it which is a noSQL database, and our analytics and data science teams wanted this data in a SQL database (a noSQL database is like storing each user’s information in a fancy text file, whereas a SQL database is more like an Excel file, where data is more organized and structured).
The key parts of ETL are Extract, Transform, and Load. Extract takes the data in a particular format and gives the rest of the system access to it; Transforms take the new messages and modify them to be more useful for the consumers of that data; Loaders deal with formatting the data correctly for where it will be stored or used.
And so we began to design the project. We started with some of the following constraints:
Good support for separation of ETL concerns. Each piece of the solution should be responsible for a limited domain, and be simple enough to quickly understand that domain when reading the code.
Performant. The solution had to be performant for up to 100s of millions of records a day, and each part of the pipeline should be performant.
Replication. We planned to deploy this architecture using Kubernetes, and wanted to make sure all aspects of the solution supported replication to deal with higher load.
Resiliency. The solution had to be resilient. Engineers needed reasonable confidence that if data was written to the application, the same data (cleaned and transformed) would be written to the analytics environment in reasonable time. We also needed to guarantee that messages would not be lost in the pipeline itself.
Extensibility. The solution had to be extensible. We should be able to add as many Extractors, Transformers, and Loaders to the ETL as we would like.
Normalization built in. We needed the ETL to be clever enough to normalize our data from the noSQL format we mentioned earlier, to relational SQL data.
Relational mandatory.
With all of the above constraints in mind, we came up with a few architectural plans. Some of them were:
- Spark jobs on an EMR cluster that would write to Redshift.
- Third party ETL solutions.
- A clone of the application db (noSQL format) for all analytics and data science.
- Go based microservices to stream the application data to a data warehouse / data lake over a message broker.
We ended up choosing the Go microservices with the message broker. The reasons for doing so were the clean separation of concerns enforced in the architecture, the performance that Go is so renowned for, the ability to easily replicate to scale various parts of the system depending on what was being loaded, and the resiliency (more on this later) of a pub-sub message broker. Finally, a big concern was that metrics would be streaming to the analytics environment in real-time instead of waiting for a large dump of the data to complete, resulting in the ability to measure nuanced experiments as they happened.
The structure sort of looked something like this:
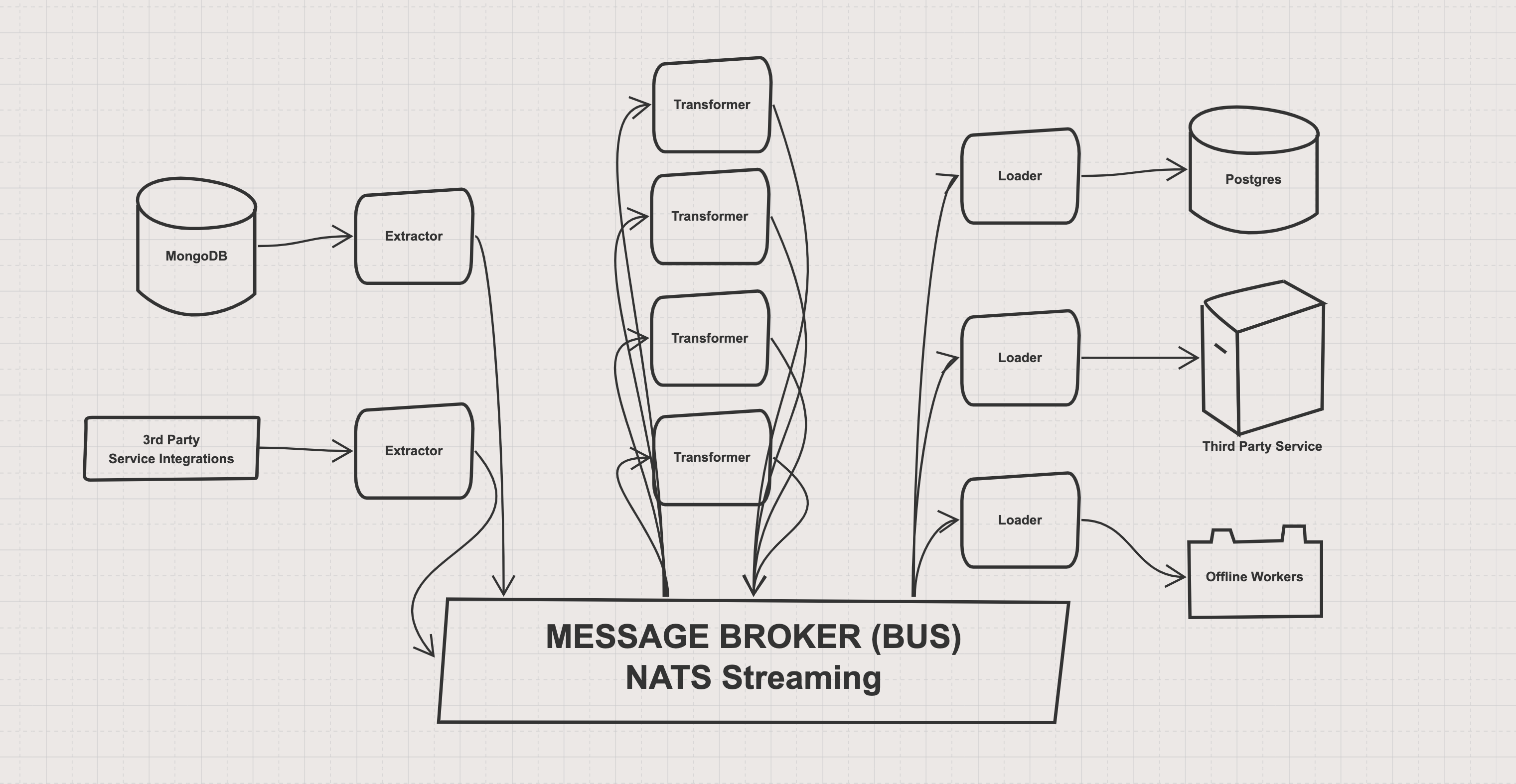
“Great! Looks like you’ve built a solid solution!” - you may say to me. What’s not to like?
There is a lot to be proud of here. The architecure scales well. The separation of concerns enforced in the architecture is beautiful. The (not pictured) ability to send one message to multiple places, and transform each set of messages to work for each loader makes extending data pipelines dead simple, with a clear code pattern. The use of Go for the solution and an open-source technology for a message broker is performant and minimal.
But with hindsight being 20⁄20, we had implemented a fatal flaw. We used a very young technology (that we self-hosted) for our message broker - NATS-Streaming. There was a few major problems with it:
The package was in beta format, and unlike its sibling NATS, seemed like it was being maintained by a small group of individuals who were unrelated to the NATS product (found this out later).
The package makes some odd, immutable decisions about implementation (queues are capped at a maximum of 1,000,000 records), and doesn’t quite alert you loudly when it is dropping messages from queues (warning alerts instead of Error alerts or Panics)
It is missing a fundamental concept of distributed systems - backpressure. NATS-Streaming has no way to account for a slow reader, or an extremely fast publisher. There are hard rate limits you can apply, but at that point you are limiting the throughput and no-longer allowing it to scale, defeating the purpose of the architecture. In my opinion this is a major oversight on the part of the NATS-streaming team, which I hope they remedy in the future.
Monitor and alert on every major point in your pipeline. If writes through a certain piece of architecture drop, you should know about it. If a piece of the architecture is hitting some kind of rate limit, you should know about it. If NATS Streaming is dropping messages, you should know about it!
NATS Streaming doesn’t offer much in the way of monitoring/visualization endpoints. It really is as minimal as it gets, which bites both ways. Make sure monitoring exists of every queue and channel of critical infrastructure like this. NATS doesn’t support this out of the box, but we were able to do this with other open source tools such as Prometheus.
Again I want to re-iterate how proud I was of what we built. I thought the lessons learned, would be useful to others considering a similar path. We eventually ended up switching to a much more durable set of SQS queues, that came with out of the box monitoring, and it has alleviated many of our problems.
There’s another (more personal) takeaway from all of this work that I would like to share. When you empower teams to access data, they will inevitably want more, and it will inevitably lead to more work for your data teams. It’s more important than ever, that companies treat data like a product, something that’s always evolving, and meant to be used by teams to deal with particular problems and pain points. If data isn’t a first class citizen, it will always feel like it’s lagging a company’s progress. I might be slightly biased.
AH